TRT-Pose에서 제공하는 2D pose esimation 모델을 NVIDIA Jetson Nano에서 실행해보았다.
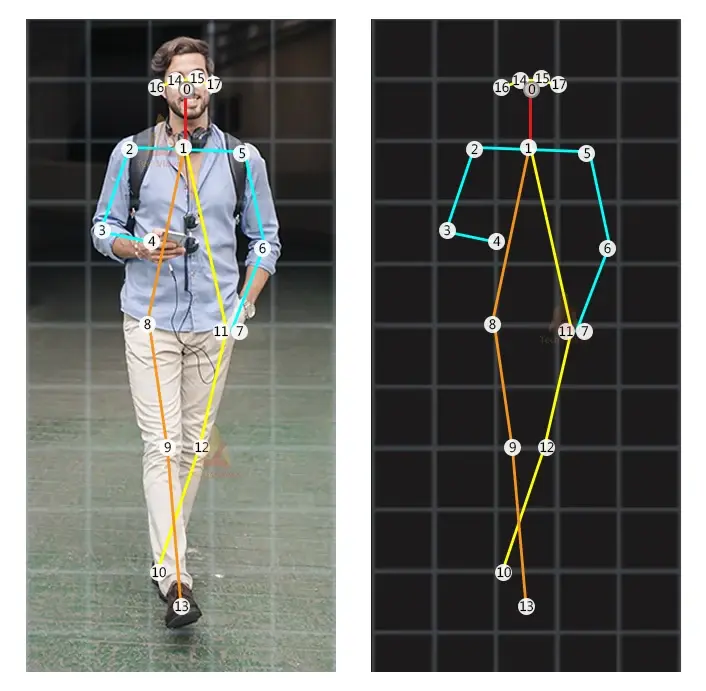
TRT-Pose는 TensorRT 프레임워크를 이용해 pose estimation 모델을 최적화했기 때문에 추론속도가 무척 빠르다.
(자세한 사항은 아래 github repository의 README 참고)
https://github.com/NVIDIA-AI-IOT/trt_pose/tree/master/trt_pose
GitHub - NVIDIA-AI-IOT/trt_pose: Real-time pose estimation accelerated with NVIDIA TensorRT
Real-time pose estimation accelerated with NVIDIA TensorRT - GitHub - NVIDIA-AI-IOT/trt_pose: Real-time pose estimation accelerated with NVIDIA TensorRT
github.com
최신Jetpack 버전에서는 가이드만 따라하면 설치하는데 문제가 없지만
구버전(Jetpack 4.2.2)에서는 버전 문제가 있어서 해당 내용을 기록해두었다.
Jetpack 4.2.2 버전에서 TRT-Pose를 설치하고 실행하는 방법은 아래와 같다.
I. TRT Pose 설치하기
TRT Pose를 실행하기 위해서는 NVIDIA Jetson 보드에 Pytorch, torchvision, torch2trt를 설치해야 한다.
Jetpack 4.2.2 버전에 맞게 Pytorch, torchvision, torch2trt 버전을 rollback하여 설치했다.
PyTorch 1.4.0 설치하기
wget <https://nvidia.box.com/shared/static/ncgzus5o23uck9i5oth2n8n06k340l6k.whl> -O torch-1.4.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev libomp-dev
pip3 install Cython
pip3 install numpy torch-1.4.0-cp36-cp36m-linux_aarch64.whl
⚠ 만약 1.7.0 버전으로 설치되는 경우
- https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-11-now-available/72048 에서 Jetpack4.2 whl 파일 직접 다운로드
Torchvision 0.5.0 설치하기
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.5.0 <https://github.com/pytorch/vision> torchvision
cd torchvision
export BUILD_VERSION=0.5.0
python3 setup.py install --user
Packaging 설치하기
pip3 install packaging
scikit-learn 설치하기
sudo apt-get install gfortran libopenblas-dev liblapack-dev
pip3 install scipy
pip3 install scikit-learn
Tortch2TRT 0.2.0 설치하기
git clone --branch v0.2.0 <https://github.com/NVIDIA-AI-IOT/torch2trt>
cd torch2trt
python3 setup.py install --user
pip3 install tqdm cython pycocotools
sudo apt-get install python3-matplotlib
TRT Pose 설치하기
pip3 install --upgrade pillow
git clone <https://github.com/NVIDIA-AI-IOT/trt_pose>
cd trt_pose
python3 setup.py install --user
II. Pretrained 모델 다운로드하기
TRT-Pose에서 미리 학습해둔 2D pose estimation 모델을 다운로드 받는다.
- trt_pose/tasks/human_pose 디렉토리 이동
cd trt_pose/tasks/human_pose
- 아래 링크 클릭해서 trt_pose/tasks/human_pose 폴더에 다운로드
resnet18_baseline_att_224x224_A_epoch_249.pth
unii@uni-jetson:~/Workspace/git/trt_pose/tasks/human_pose$ ls
# download_coco.sh live_demo.ipynb
# eval.ipynb main.py
# experiments preprocess_coco_person.py
# human_pose.json resnet18_baseline_att_224x224_A_epoch_249.pthIII. 파이썬 스크립트 작성하고 실행하기
USB 카메라로부터 이미지를 읽어오고, 2D pose estimation을 수행하는 파이썬 스크립트를 작성했다.
실행해보면 카메라 영상위에 2D keypoint가 프린트되는 것을 확인할 수 있다.
(Jetson Nano 기준으로 FPS는 약 10~12)
vim main.py
- main.py 스크립트에 아래 코드를 복사 및 붙여넣기
# main.py
import json
import trt_pose.coco
import trt_pose.models
import torch
import torch2trt
from torch2trt import TRTModule
import time, sys
import cv2
import torchvision.transforms as transforms
import PIL.Image
from trt_pose.draw_objects import DrawObjects
from trt_pose.parse_objects import ParseObjects
import argparse
import os.path
'''
hnum: 0 based human index
kpoint : keypoints (float type range : 0.0 ~ 1.0 ==> later multiply by image width, height
'''
def get_keypoint(humans, hnum, peaks):
#check invalid human index
kpoint = []
human = humans[0][hnum]
C = human.shape[0]
for j in range(C):
k = int(human[j])
if k >= 0:
peak = peaks[0][j][k] # peak[1]:width, peak[0]:height
peak = (j, float(peak[0]), float(peak[1]))
kpoint.append(peak)
#print('index:%d : success [%5.3f, %5.3f]'%(j, peak[1], peak[2]) )
else:
peak = (j, None, None)
kpoint.append(peak)
#print('index:%d : None %d'%(j, k) )
return kpoint
parser = argparse.ArgumentParser(description='TensorRT pose estimation run')
parser.add_argument('--model', type=str, default='resnet', help = 'resnet or densenet' )
args = parser.parse_args()
with open('human_pose.json', 'r') as f:
human_pose = json.load(f)
topology = trt_pose.coco.coco_category_to_topology(human_pose)
num_parts = len(human_pose['keypoints'])
num_links = len(human_pose['skeleton'])
if 'resnet' in args.model:
print('------ model = resnet--------')
MODEL_WEIGHTS = 'resnet18_baseline_att_224x224_A_epoch_249.pth'
OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A_epoch_249_trt.pth'
model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval()
WIDTH = 224
HEIGHT = 224
else:
print('------ model = densenet--------')
MODEL_WEIGHTS = 'densenet121_baseline_att_256x256_B_epoch_160.pth'
OPTIMIZED_MODEL = 'densenet121_baseline_att_256x256_B_epoch_160_trt.pth'
model = trt_pose.models.densenet121_baseline_att(num_parts, 2 * num_links).cuda().eval()
WIDTH = 256
HEIGHT = 256
data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda()
if os.path.exists(OPTIMIZED_MODEL) == False:
model.load_state_dict(torch.load(MODEL_WEIGHTS))
model_trt = torch2trt.torch2trt(model, [data], fp16_mode=True, max_workspace_size=1<<25)
torch.save(model_trt.state_dict(), OPTIMIZED_MODEL)
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL))
t0 = time.time()
torch.cuda.current_stream().synchronize()
for i in range(50):
y = model_trt(data)
torch.cuda.current_stream().synchronize()
t1 = time.time()
print(50.0 / (t1 - t0))
mean = torch.Tensor([0.485, 0.456, 0.406]).cuda()
std = torch.Tensor([0.229, 0.224, 0.225]).cuda()
device = torch.device('cuda')
def preprocess(image):
global device
device = torch.device('cuda')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = PIL.Image.fromarray(image)
image = transforms.functional.to_tensor(image).to(device)
image.sub_(mean[:, None, None]).div_(std[:, None, None])
return image[None, ...]
def execute(img, src, t):
color = (0, 255, 0)
data = preprocess(img)
cmap, paf = model_trt(data)
cmap, paf = cmap.detach().cpu(), paf.detach().cpu()
counts, objects, peaks = parse_objects(cmap, paf)#, cmap_threshold=0.15, link_threshold=0.15)
fps = 1.0 / (time.time() - t)
for i in range(counts[0]):
keypoints = get_keypoint(objects, i, peaks)
for j in range(len(keypoints)):
if keypoints[j][1]:
x = round(keypoints[j][2] * WIDTH * X_compress)
y = round(keypoints[j][1] * HEIGHT * Y_compress)
cv2.circle(src, (x, y), 3, color, 2)
cv2.putText(src , "%d" % int(keypoints[j][0]), (x + 5, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 1)
cv2.circle(src, (x, y), 3, color, 2)
print("FPS:%f "%(fps))
#draw_objects(img, counts, objects, peaks)
cv2.putText(src , "FPS: %f" % (fps), (20, 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1)
#out_video.write(src)
return src
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
# ret_val, img = cap.read()
# fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
# out_video = cv2.VideoWriter('/tmp/output.mp4', fourcc, cap.get(cv2.CAP_PROP_FPS), (640, 480))
# count = 0
X_compress = 640.0 / WIDTH * 1.0
Y_compress = 480.0 / HEIGHT * 1.0
if cap is None:
print("Camera Open Error")
sys.exit(0)
parse_objects = ParseObjects(topology)
draw_objects = DrawObjects(topology)
while cap.isOpened() and True:
t = time.time()
ret_val, dst = cap.read()
if ret_val == False:
print("Camera read Error")
break
img = cv2.resize(dst, dsize=(WIDTH, HEIGHT), interpolation=cv2.INTER_AREA)
src = execute(img, dst, t)
cv2.imshow('src', src)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#count += 1
cv2.destroyAllWindows()
#out_video.release()
cap.release()
'💻 programming' 카테고리의 다른 글
| crontab으로 파이썬 스크립트 예약 작업하기 (+동작안할 때) (0) | 2023.04.14 |
|---|---|
| [트위터-티스토리] 트위터 오픈 API 등록하기, 개발자 계정 신청하기, tweepy 실시간 트렌드 가져오기 <3> (3) | 2022.12.29 |
| [bash] 리눅스 터미널에 웰컴 메시지 출력하기 (0) | 2022.12.23 |
| [SSH] 리눅스 로그인 웰컴 메시지 만들기 (0) | 2022.12.23 |
| [트위터-티스토리] 티스토리 오픈 API 등록하기, Access token 발급받기, 카테고리 목록 가져오기 <2> (0) | 2022.12.21 |



댓글