https://tutorials.pytorch.kr/beginner/finetuning_torchvision_models_tutorial.html
pytorch 영문 튜토리얼을 내 맘대로 해석해서 작성하는 포스팅입니다
FINETUNING TORCHVISION MODELS
본 페이지는 torchvision 모델을 어떻게 finetune하고 feature를 추출하는가에 대한 튜토리얼입니다
CNN 모델은 각자 목적에 맞게 설계되었으므로 모든 상황에 적용하기는 어렵습니다
따라서, 연구자가 기존 CNN 모델을 잘 분석하고 상황에 맞게 이용하는 것이 무엇보다 중요합니다
이번 튜토리얼은 데이터셋이 조금 바뀌었을 뿐인데 처음부터 다시 모델을 훈련시켜야 하나?
혹시 내가 원하는 2가지 클래스만 분류하는 모델로 쉽게 바꿀 순 없을까에 대한 답이 될 수 있습니다
기존 CNN 모델을 customize하기 위한 방법은 크게 두 가지입니다 (finetuning, feature extraction)
본 튜토리얼에서는 feature extraction에 대해 설명합니다 (코드는 finetuning도 수행할 수 있도록 구현되어 있습니다)
- finetuning
- pretrained 모델을 이용하되, 모델의 모든 파라미터를 업데이트하는 방법
- feature extraction
- pretrained 모델을 가져와서, 마지막 FC 레이어만 우리가 원하는 목적에 맞게 weight를 업데이트하는 방법
- pretrained 모델을 이용해 이미지 특성(feature)을 가져오는 부분을 수정하지 않기 때문에 feature extraction이라 부름
- 오직 수정되는 부분은 마지막 FC에 해당하는 output layer
finetuning과 feature extraction 모두 다음 단계를 통해 수행됩니다
- pretrained 모델 초기화
- final layer reshape (클래스 개수를 목적에 맞게 수정하기 위해)
- optimization algorithm 정의
- training
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("Pytorch version: ", torch.__version__)
print("Torchvision version: ", torchvision.__version__)Pytorch version: 1.13.0+cu117
Torchvision version: 0.14.0+cu117Inputs (입력)
입력으로는 hymenpotera_data 데이터셋을 이용합니다 (여기: 벌, 개미 두가지 클래스에 대한 데이터셋)
- hymenpotera_data는 ImageFoler 데이터셋 구조에 맞게 저장되어 있습니다 (custom dataset 정의 필요 X)
num_classes: 데이터셋의 클래스 개수 (검출하려고 하는 객체의 개수)batch_size: 배치 크기 (모델 학습에 사용하는 HW 성능과 관련된 파라미터)num_epochs: 훈련 에폭수feature_extract: boolean(참/거짓), True-> feature_extract, False->fine_tuning- feature extract가
True이면 마지막 레이어의 weight만 업데이트되고 나머지 weight는 고정됨
- feature extract가
data_dir = "./hymenoptera_data/"
model_name = "squeezenet" # resnet, alexnet, vgg, squeezenet, densenet
# VGGNet(arXiv/2014), ResNet(CVPR/2016), Densenet(CVPR/2017)
num_classes = 2
batch_size = 8
num_epochs = 15
feature_extract = TrueHelper Functions
모델을 수정하기 전에 몇가지 Helper function을 정의합니다
train_model 함수는 training과 validation을 수행하는 함수입니다
- 입력으로 model, dataloaders, loss function, optimizer, epoch 수를 받습니다
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0 #accuracy
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs-1))
print('-' * 10)
# 에폭 하나를 수행할 때마다 training과 validation을 수행
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0 # loss 초기화
running_corrects = 0 # corrects 초기화
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 학습 단계 (loop)에서 최적화는 세단계로 이루어짐
## optimizer.zero_grad()를 호출하여 모델 매개변수의 변화도를 재설정
## 기본적으로 변화도는 더해지기 때문에 중복 계산을 막기 위해 반복할 때마다 명시적으로 재설정(0 할당)
## loss.backwards()를 호출하여 prediction loss를 back-propagation함
## 변화도를 계산한 뒤에는 optimizer.step()을 호출하여 수집된 변화도로 매개변수를 조정
# gradients 파라미터를 0으로 초기화
optimizer.zero_grad()
# train일 때는 history를 추적
with torch.set_grad_enabled(phase=='train'):
# forward
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize (training 일 때만)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data) # prediction이 바르게 횟수
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
# double() 메서는 tensor의 내장 메서드로 tensor element를 모두 double 형으로 변환
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history
set_parameter_requires_grad
feature를 추출할 때 모델의 attribute 파라미터 .requires_grad를 False 만들어주는 helper function을 정의합니다
일반적으로 pretrained 모델을 로드하면 모델의 모든 파라미터는 .requires_grad=True를 가지는데
우리가 처음부터 새로 모델을 훈련하거나 finetuning 할 때는 괜찮지만 단순히 feature extraction만 하눈 경우에는 새로 추가된 레이어만 gradients를 계산하면 됩니다 (나머지 레이어는 gradients 계산 X)
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False네트워크 초기화 및 재구조화하기
지금부터가 가장 흥미로운 내용입니다. 우리는 네트워크를 구조를 다시 설계할 것입니다
이러한 과정은 자동화되어 있지 않으므로 재구조화하려는 모델의 특성을 고려하여 작업해야 합니다
CNN 모델의 마지막 레이어 (대부분 FC 레이어)는 분류하려는 클래스의 개수와 같은 개수의 노드로 구성되어 있습니다
Imagenet에서 학습된 모델들은 1000개의 클래스를 학습하였고, 마지막 FC레이어는 1000개의 노드로 구성되어 있습니다
우리가 해야 하는 것은 1000개 크기의 output 레이어를 2개의 레이어로 변환하는 것입니다 (벌, 개미 클래스 분류)
네트워크를 재구조화 할 때도 finetuning과 feature extraction를 각각 고려하여 수정해야 합니다
feature extraction
- 오직 마지막 레이어의 파라미터(weight, bias)만 업데이트합니다
- 바꿔 말하면 마지막 레이어를 제외한 나머지 레이어는 업데이트할 필요가 없습니다
- 업데이트를 막는 쉬운 방법이
.requires_gradattribute를False로 설정하는 것입니다 - (주의) 기본적으로
.requires_grad는True이므로 반드시 수동으로 설정해야 합니다
finetuning
- finetuning은
.requires_grad를True그대로 두면 됩니다 (Default =True)
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# Initialize these variables which will be set in this if statement. Each of these
# variables is model specific.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract) # set requires grad as False if feature_extract
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
# Initialize the model for this run
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# Print the model we just instantiated
print(model_ft)Load Data
모델의 input size가 고정되어 있으므로, 우리는 데이터셋의 이미지를 모델에 적합한 형태로 변환해야 합니다
- train 데이터셋: 데이터 증강 + 정규화 수행
- 데이터셋 내 이미지의 특성이 심하게 차이가 나는 경우 모델 학습이 잘 되지 않기 때문에 정규화를 합니다
- 평범한 이미지의 경우는 (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)으로 정규화하는 것을 추천하고 있습니다
- valid 데이터셋: 데이터 정규화만 수행
# train 데이터셋: 데이터 증강 및 정규화 => 데이터가 가진 feature의 스케일이 심하게 차이가 나는 경우 문제가 되기 때문에
# valid 데이터셋: 데이터 정규화 (증강 X)
# 만약, 일반적인 조도, 각도, 배경을 포함하는 평범한 이미지의 경우는 (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)으로 정규화하는 것을 추천한다는 커뮤니티 의견이 지배적
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in ['train', 'val']}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")Optimizer 만들기
모델 구조를 수정했다면, 마지막 과정은 원하는 파라미터만 업데이트할 수 있도록 optimizer를 만드는 것입니다
원하는 파라미터가 잘 disabled 되었는지 확인하기 위해서 파라미터를 출력해 보고 확인해보아야 합니다
-
- finetuning의 경우 모든 레이어의
.require_grad가True인지 - feature extracting의 경우 마지막 레어어만
.require_grad가True인지
- finetuning의 경우 모든 레이어의
model_ft = model_ft.to(device)
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t", name)
else:
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t", name) # Do nothing
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)Params to learn:
classifier.1.weight
classifier.1.biasTraining / Validation
정말 정말 마지막 남은 단계는 모델의 loss function을 정의하고 훈련과 검증을 반복하는 것입니다
epoch의 개수, learning rate들은 각자 모델에 맞게 최적화할 수 있도록 결정해야 합니다
criterion = nn.CrossEntropyLoss()
model_ft, hist = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft, num_epochs=num_epochs)class_names = image_datasets['train'].classes
def visualize_model(model, num_images=6):
images_so_far = 0
fig = plt.figure()
for i, data in enumerate(dataloaders_dict['val']):
inputs, labels = data
outputs = model(inputs.to(device))
_, preds = torch.max(outputs.data, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
plt.imshow(inputs.cpu().data[j].T)
if images_so_far == num_images:
return
visualize_model(model_ft)finetuning한 모델이 정말 벌과 개미를 분류할 수 있는지 확인하기 위해 그림을 그려보았습니다
아래 그림을 보면 벌과 개미를 어느정도 구분하는 것을 볼 수 있습니다 (이미지는 정규화 과정을 통해 채도, 명도가 변경되었습니다)

처음부터 설계한 모델과 비교하기
만약 transfer learning 없이 직접 모델을 처음부터 훈련했다면 어땠을까요?
scratch_model,_ = initialize_model(model_name, num_classes, feature_extract=False, use_pretrained=False)
scratch_model = scratch_model.to(device)
scratch_optimizer = optim.SGD(scratch_model.parameters(), lr=0.001, momentum=0.9)
scratch_criterion = nn.CrossEntropyLoss()
_,scratch_hist = train_model(scratch_model, dataloaders_dict, scratch_criterion, scratch_optimizer, num_epochs=num_epochs)
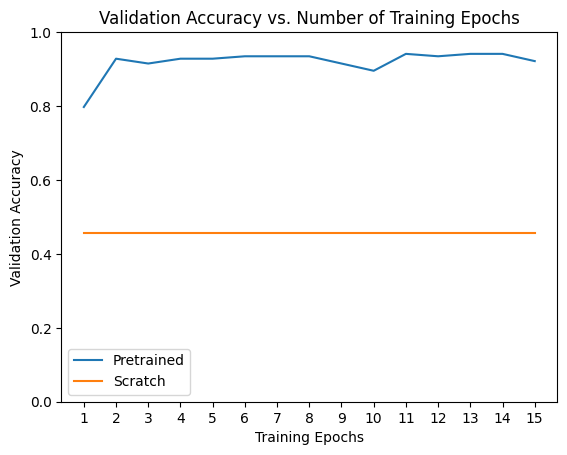
# Plot the training curves of validation accuracy vs. number
# of training epochs for the transfer learning method and
# the model trained from scratch
ohist = []
shist = []
ohist = [h.cpu().numpy() for h in hist]
shist = [h.cpu().numpy() for h in scratch_hist]
plt.title("Validation Accuracy vs. Number of Training Epochs")
plt.xlabel("Training Epochs")
plt.ylabel("Validation Accuracy")
plt.plot(range(1,num_epochs+1),ohist,label="Pretrained")
plt.plot(range(1,num_epochs+1),shist,label="Scratch")
plt.ylim((0,1.))
plt.xticks(np.arange(1, num_epochs+1, 1.0))
plt.legend()
plt.show()
visualize_model(scratch_model)Epoch 진행에 따른 finetuning 모델과 scratch 모델의 정확도를 그래프로 표현해보면 아래와 같습니다
14번의 짧은 Epoch 수에도 불구하고 pretrained된 모델을 이용한 경우 정확도가 약 90%이지만
scratch 모델의 정확도는 약 50%도 채 되지 않습니다
실제 분류 결과를 그림으로 확인해보아도 scratch 모델은 벌과 개미를 잘 구분하지 못하는 모습입니다

jupyter notebook은 아래에
'💻 programming > ml' 카테고리의 다른 글
| [tensorflow] model.fit 에러 : libdevice not found (3) | 2023.10.18 |
|---|---|
| Openpose 에러: cudnn_status_not_initialized (0) | 2023.07.20 |

댓글