기본 정렬 (Elementary Sort)
1. Comparable Interface
어떤 자료를 정렬하기 위해서는 대소관계를 판단할 수 있어야 합니다. Java에서는 대소관계를 판단할 수 있는 함수를 가지고 있다는 것을 보증하기 위해 Comparable Interface를 사용합니다. 이 인터페이스는 compareTo( )라는 메서드를 가지는데, 두 객체의 대소관계를 판단하여 작음(-1), 같음 (0), 큼(1)을 반환합니다.
1.1 Total order
객체의 크기가 비교 가능하려면 다음 규칙을 만족해야 합니다
v ≤ w 이고 w ≤ v 이면 v = w이다
v ≤ w 이고 w < x 이면 v ≤ x이다
v ≤ w 거나 w ≤ v 이다
1.2 Sort algorithm (c++)
c++은 quick sort를 기반으로한 함수를 제공하고 있습니다. 평균 시간복잡도는 nlogn입니다.
// #include <algorithm>
template <typename T>
void sort(T start, T end);
template <typename T>
void sort(T start, T end, Compare comp);
// example
// sort(v.begin(), v.end());기본 자료형이 아닌 새로운 객체를 작성한 경우에는 비교 연산자를 재정의하여 전달할 수 있습니다.
#include<iostream>
#include<algorithm>
#include<vector>
#include<ctime>
using namespace std;
class Student{
public:
string name;
int age;
Student(string name, int age):name(name),age(age){}
bool operator<(Student s) const{ //연산자 오버로딩(operator overloading)
if(this->name == s.name){
return this->age < s.age;
}else{
return this->name < s.name;
}
}
};
int main(void){
vector<Student> v;
v.push_back(Student("cc", 10));
v.push_back(Student("ba", 24));
v.push_back(Student("aa", 11));
v.push_back(Student("cc", 8)); //cc는 이름이 같으니 나이 기준 오름차순 예시
v.push_back(Student("bb", 21));
sort(v.begin(), v.end()); //[begin, end) 연산자 오버로딩 이용한 정렬.
return 0;
}2. Selection sort (선택 정렬)
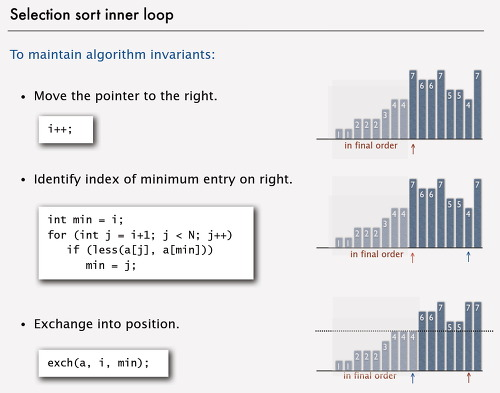
가장 쉽게 떠올릴 수 있는 정렬 알고리즘으로, [i, n]의 원소들 중 가장 작은 원소 위치 j를 찾아서 i와 j 원소를 교환하는 방법으로 정렬합니다. i를 배열의 최대 크기 n까지 반복하면 모든 원소가 정렬됩니다.
2.1 선택 정렬 알고리즘의 특징
- 장점: 교환 횟수가 항상
n번 수행 - 단점: 배열이 정렬되어 있더라도 항상
(n^2)/2번 비교
3. Insertion sort (삽입 정렬)
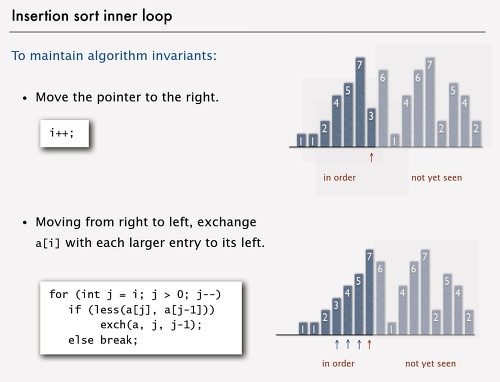
삽입 정렬은 말 그대로 크기를 비교하여 원소를 삽입하는 정렬 알고리즘입니다. 손안의 카드를 정렬하는 방법과 유사합니다.
- 왼손에는 정렬되어 있는 카드를 올려둔다
- 오른손에는 정렬되지 않은 카드를 올려둔다
- 오른손에서 카드를 뽑아서 왼손으로 옮긴다 (올바른 자리에 삽입한다)
- 오른손에 카드가 모두 없어질 때까지 반복한다

3.1 삽입 정렬 알고리즘의 특징
- 장점: 배열이 이미 정렬되어 있는 경우 매우 효율적 (
n-1번의 단순 비교만 수행) - 단점: 비교적 원소 교환이 잦음, 최악의 경우 시간 복잡도는
O(n^2)(배열이 역순으로 정렬된 경우)
4. Shell Sort (셸 정렬)
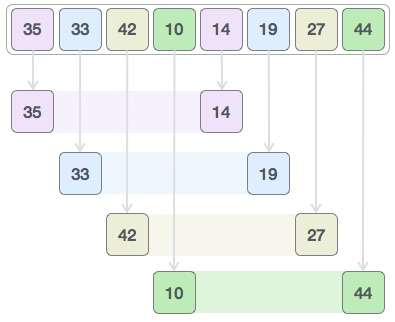
가장 오래된 정렬 알고리즘의 하나로, 삽입 정렬의 단점을 보완한 정렬 알고리즘입니다. 셸 정렬은 분할 정복을 이용합니다.
- 정렬해야 할 배열을
k개의 부분 배열로 만든다k를 gap이라하고 리스트의k번째 요소를 추출하여 부분 배열을 만든다k의 초기값은n/2
- 부분 배열을 삽입 정렬로 정렬한다
- 간격
k를 절반으로 줄이고k가1이 될 때까지 반복한다 (짝수인 경우 +1을 해서 홀수로 만든다)
4.1 셸 정렬 알고리즘의 특징
- 장점: 평균 시간 복잡도는
O(n^1.5)(실험적인 연구를 통해 증명된 결과) - 단점: 최악의 경우 시간 복잡도는
O(n^2)
5. Shuffling
카드를 섞는 셔플링은 정렬과 깊은 관계가 있습니다. 각 배열에 임의의 값을 부여할 수만 있다면 배열을 정렬하는 것만으로도 카드를 섞을 수 있습니다. 그런데 사실 카드를 잘 섞는 것은 매우 어려운 일입니다. 임의의 값을 균등하게 배정하는 것이 무척 힘들기 때문입니다.
흔히 보는 랜덤은 정말로 임의의 값이 아니고 특정한 방법으로 계산하거나 몇 밀리초(ms) 단위로 시시각각 변하는 값을 초기값으로 잡은 다음 여러 계산 과정을 거쳐 사람이 볼 때에는 마치 임의의 값인 것처럼 보이게 하는 것으로 의사난수(Pseudo Random)라고 합니다.
예를 들어 1997년 개발된 MT19937를 사용하는 경우 32bit까지는 동일 분포를 보장하지만 셔플링할 수 있는 최대 갯수가 32bit를 넘어서면 랜덤과 서버 시간과의 연관관계를 파악할 수 있게 됩니다.

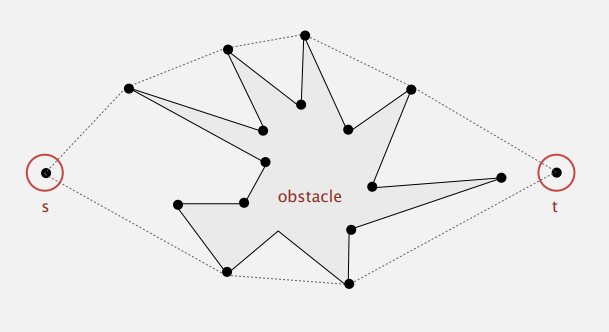
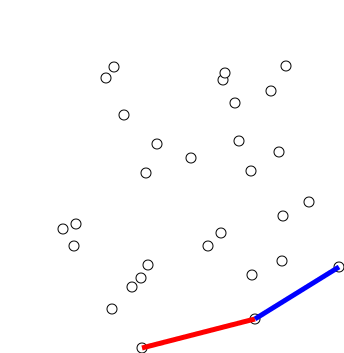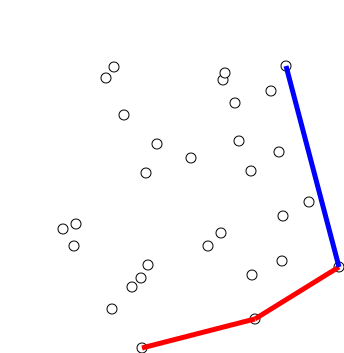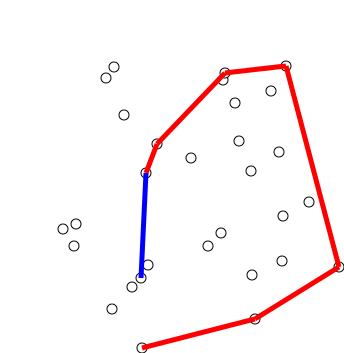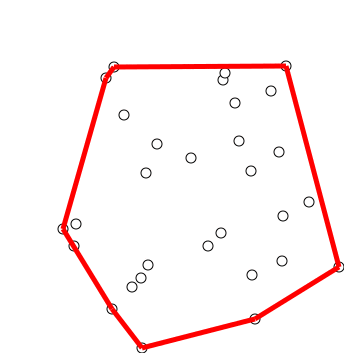
6. Convex hull (볼록 껍질)
볼록 껍질 알고리즘은 다양한 객체에 볼록 껍질을 만드는 알고리즘입니다. 볼록 껍질 알고리즘은 수학 및 컴퓨터 과학에 광범위하게 적용되고 있습니다.
6.1 Graham's Scan
그레이엄 스캔 알고리즘은 오직 시계 방향으로
- 첫 단계로 y좌표가 가장 작은 점을 찾는다
- 점 P와 점들의 집합이 x축에 대해 이루는 각도가 증가하는 순으로 정렬된다
- 알고리즘은 정렬된 배열의 각 점들에 대해 순차적으로 처리한다
- 항상 좌회전 하는 점만 선택한다...
'💻 programming > algorithm' 카테고리의 다른 글
| 퀵 소트 (Quicksort) - c/c++ (0) | 2021.05.05 |
|---|---|
| 기초 기호 표 (Elementary Symbol Table) (0) | 2021.03.26 |
| 최대 합 부분 배열 (Maximum sub-array problem) (0) | 2021.02.26 |



댓글